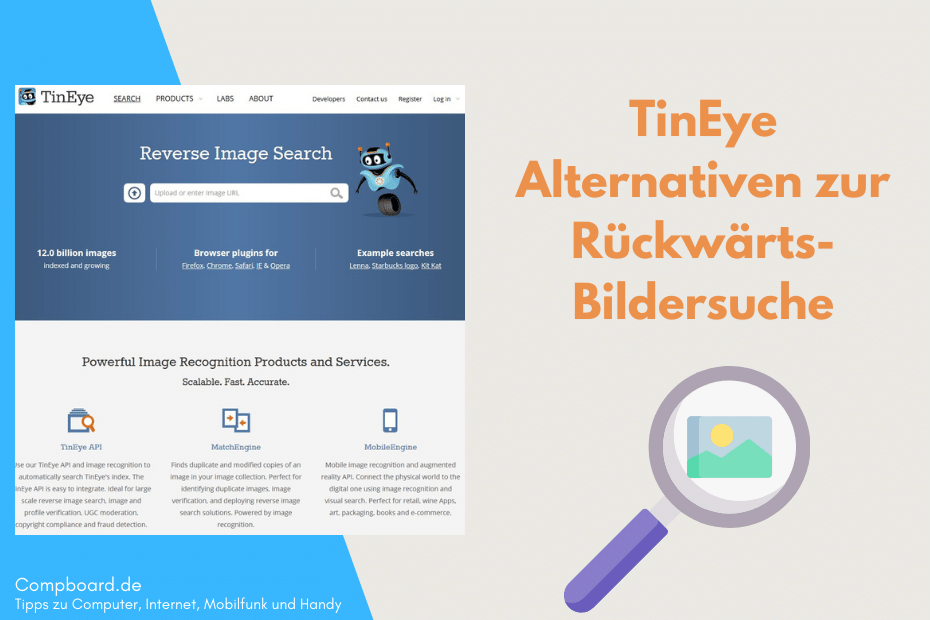
Originale Bildquelle finden & Objekte auf Fotos identifizieren
Passende Bilder zu finden ist heutzutage nicht mehr schwierig, aber wenn man die originale Bildquelle eines bereits vorhandenen Bildes finden will, sieht die Sache schon… Weiterlesen »Originale Bildquelle finden & Objekte auf Fotos identifizieren